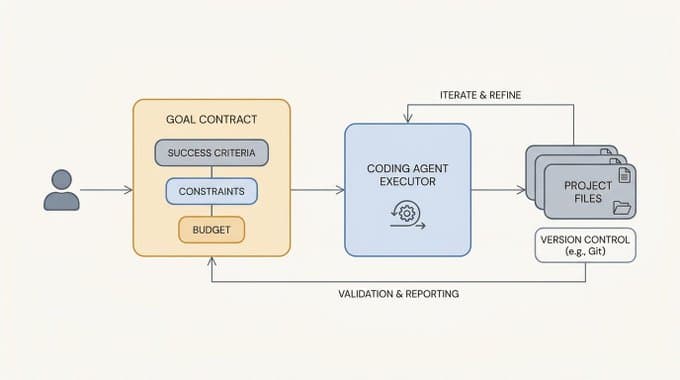
Recursive Language Models (RLMs) argued that models should actively manage context by writing code in a REPL. LCM (Lossless Context Management) keeps that core idea but moves control of memory operations into a deterministic engine.
The trade-off is simple. RLM optimizes for autonomy. LCM optimizes for guarantees. The result is Volt, an open-source coding agent that outperforms Claude Code on the OOLONG benchmark across 32K to 1M context lengths, all using the same base model (Opus 4.6).
Think of LCM as moving memory control from "the model improvises each time" to "the runtime enforces consistent rules." The model still reasons about the task. It just no longer has to reinvent chunking, retries, and context compression on every run.
In practice, that means
- The model focuses on solving the user's problem.
- The engine handles context logistics deterministically.
- You get better reliability at long context without adding overhead to short tasks.
Say you ask a coding agent to refactor 50 files across a large repo. With a model-driven approach (like RLM), the model has to write its own chunking logic, decide how to batch those files, handle retries when context fills up, and compress old results, all while solving the actual refactoring problem. Every run can play out differently depending on what the model improvises. With LCM, the model just calls llm_map once over the 50 files. The engine handles batching, parallelism, retries, and context limits behind the scenes. The model stays focused on the refactoring logic itself.
Autonomy vs. Guarantees
The paper draws an analogy to GOTO versus structured programming. Unrestricted GOTO is maximally flexible but hard to reason about. Structured primitives like for, while, and if/else remove some expressive freedom but make systems predictable and debuggable.
RLM sits on the GOTO side. The model writes arbitrary recursion and control flow. LCM sits on the structured side. The model gets constrained operators, and the engine owns iteration, retries, and state transitions.
The problem with model-written orchestration is variance. A good chunking strategy in one run can degrade in the next. And if every turn pays recursion overhead just to support rare long-context tasks, you lose latency and cost efficiency on normal workloads.
Two Layers of State
LCM splits memory into two layers.
The Immutable Store is the source of truth. Every message and tool result is appended verbatim and never mutated.
The Active Context is the working set shown to the model. It contains recent raw turns plus summary nodes for older spans. These summaries are derived views, not the source of truth. The original data is always retrievable via lcm_expand.

The engine enforces soft and hard token thresholds. Below the soft threshold, nothing happens beyond logging. Above the soft threshold, the engine compacts asynchronously and swaps in the compressed node between turns. Users only see added latency if activity spikes fast enough to hit the hard threshold during compaction.
This is the paper's Zero-Cost Continuity claim. Most turns stay inside native context and pay zero orchestration tax.
Three-Level Escalation
A known failure mode in long sessions is compaction that doesn't actually compact. The model outputs something longer than the input, and the memory loop stalls.
LCM forces convergence with three escalation levels.

- Level 1 is normal detail-preserving summary.
- Level 2 uses aggressive compression at half the target size.
- Level 3 does deterministic truncation with no model inference. This guarantees termination.
This is the kind of boring safety rail that makes or breaks multi-hour agent runs. In the worst case you get lossy truncation, not a stuck system.
Large File Handling
One file dump can consume an entire context window. LCM handles this with a file-size threshold.
- Small files enter context directly.
- Large files stay external. Context gets a compact handle plus an Exploration Summary.
The summary is type-aware. JSON, CSV, and SQL files get schema and shape extraction. Code gets structural summaries like functions and classes. Plain text gets LLM summarization.
The model keeps useful awareness without loading full payloads. Raw files remain on disk, not in the immutable store. This matches real coding scenarios where artifacts can be gigabytes.
Operator-Level Recursion
This is LCM's biggest departure from RLM.
RLM uses symbolic recursion where the model writes loops and orchestration code itself. LCM uses operator-level recursion where the model calls deterministic primitives like llm_map and agentic_map.

LLM-Map runs one stateless LLM call per JSONL item. Built for extraction, classification, and scoring. The engine handles concurrency (default 16 workers), JSON Schema validation, and automatic retries with validator feedback.
Agentic-Map runs one sub-agent per item when tool use is required.
In both modes, the model states intent once and the engine executes the loop. No need to implement parallelism or retry logic in generated code.

Figure 5 makes the contrast concrete. RLM asks the model to author a loop. LCM asks it to call a map operator once. Iteration, retries, and validation all move into deterministic runtime code.
Guarding Against Infinite Delegation
Delegation can loop forever if agents keep handing identical tasks to child agents. LCM adds a scope-reduction invariant. A non-root agent must declare both the delegated scope and retained work when spawning a child. If retained work is empty or vague, the engine rejects the delegation.
This creates a well-founded recursion tree without arbitrary depth caps. Each step must reduce remaining responsibility.
Results
Volt and Claude Code were evaluated on OOLONG (trec_coarse), a long-context aggregation benchmark. Both used Opus 4.6 as the primary model, with Haiku 4.5 for high-throughput subtasks.
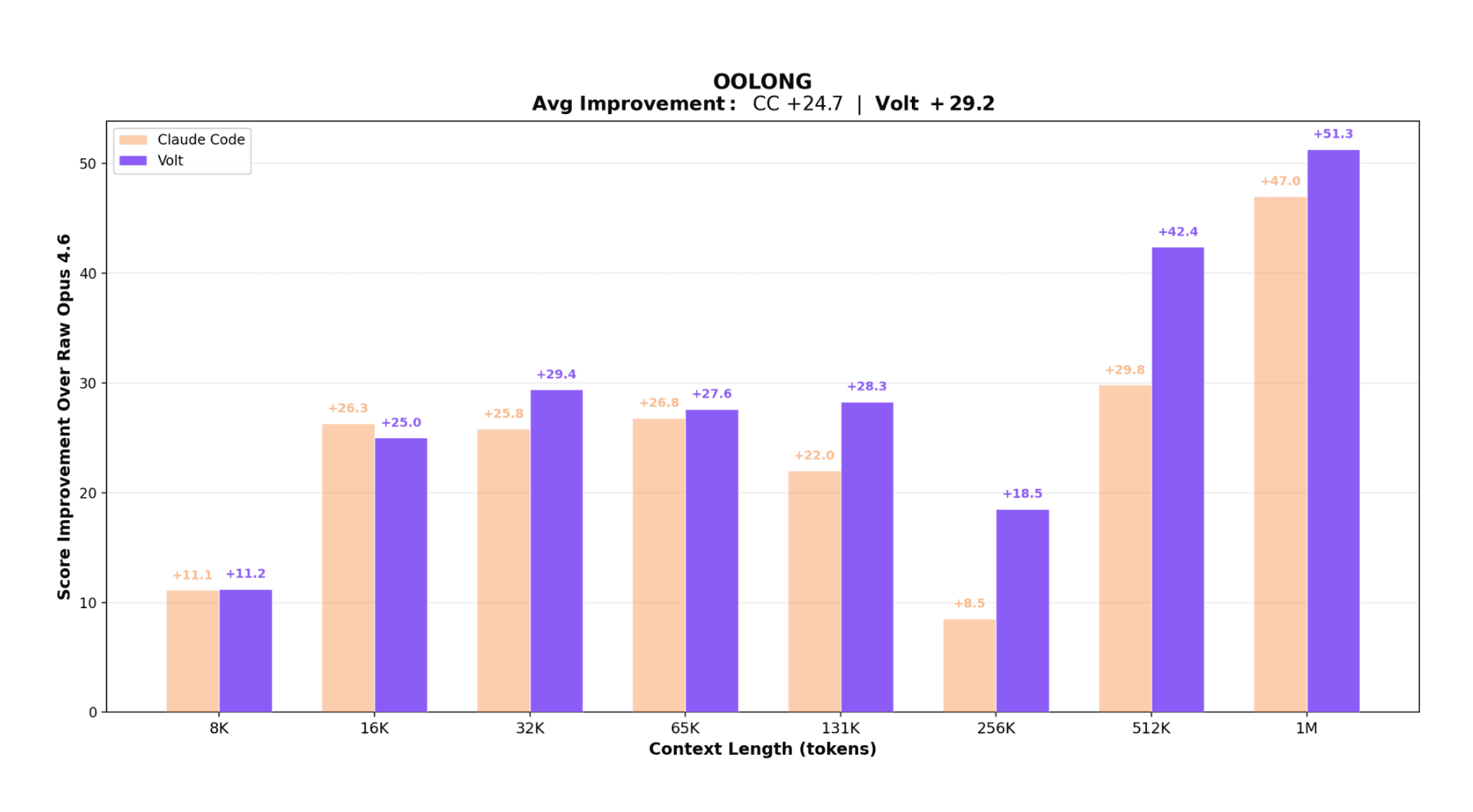
Volt scored 74.8 average vs. Claude Code's 70.3 (+4.5). Relative to raw Opus 4.6, Volt gained +29.2 and Claude Code gained +24.7.
The regime split matters. Below 32K, performance is similar and Claude Code is slightly ahead at 8K and 16K. From 32K through 1M, Volt leads at every tested length, with the gap widening past 131K. The deltas are +10.0 at 256K, +12.6 at 512K, +4.3 at 1M.
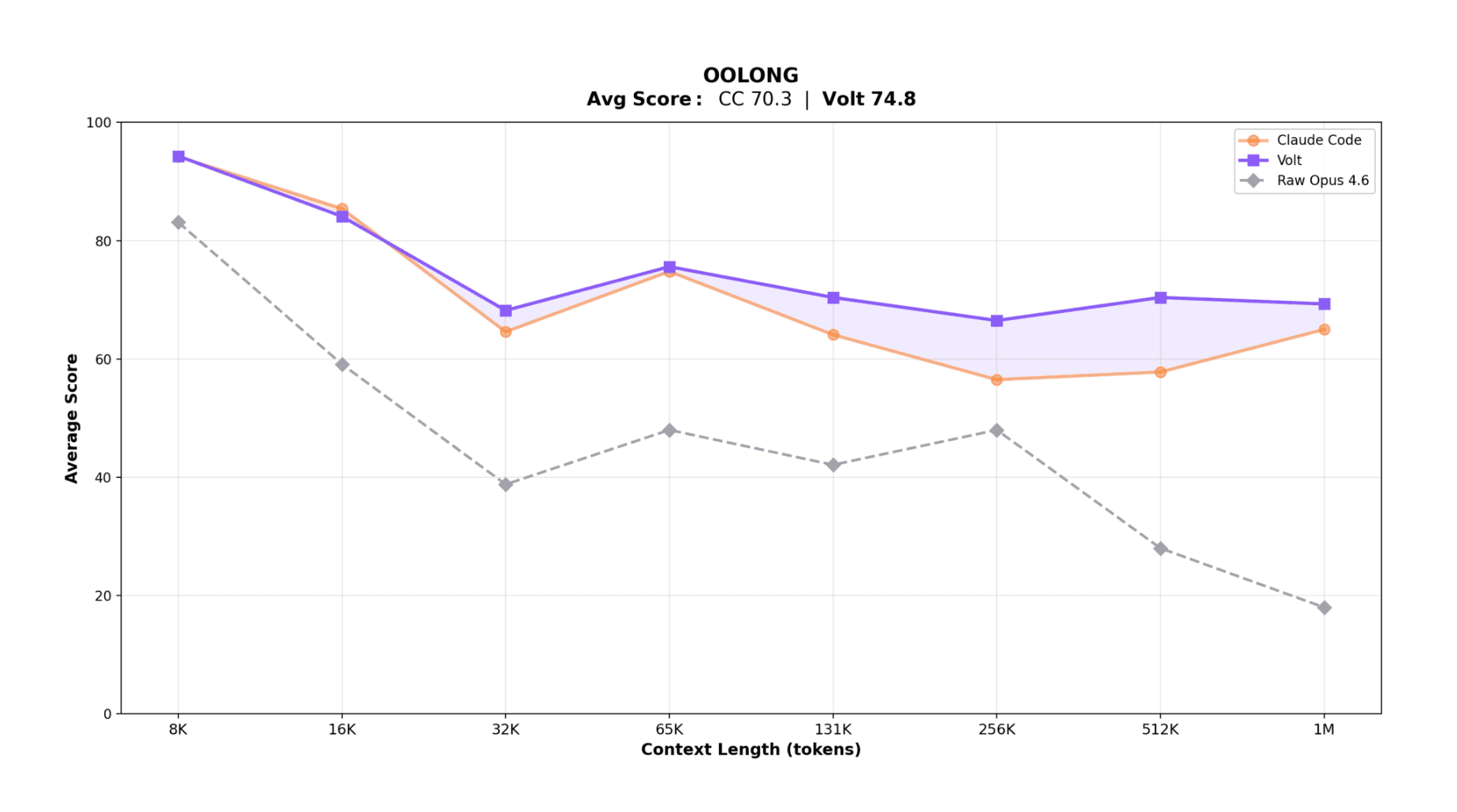
Raw Opus 4.6 degrades sharply past 65K and drops below 20 at large lengths. Both agentic systems help, but Volt is more stable at scale.
Why? At long lengths, Claude Code often depends on model-authored chunking and rollup logic. Volt offloads those loops to LLM-Map, outside active context, with deterministic execution and typed outputs. Less context saturation, less orchestration variance.
Worth calling out. OOLONG stresses decomposition, consistency, and aggregation over many items. Orchestration quality directly affects score. In this regime, architecture can dominate base-model capability.
The model didn't change between Volt and Claude Code. The control plane changed. That should update how we think about agent progress. A lot of headroom still exists in runtime design, even with fixed frontier models.
There's also a reproducibility benefit. If iteration and retry are model-authored, two runs can diverge for hard-to-isolate reasons. If those paths are deterministic engine logic, debugging looks more like software engineering and less like prompt archaeology.
LCM vs. RLM
LCM doesn't reject RLM's premise. It reframes who owns the mechanism. Both assume context management should be active. They differ on control.
| RLM | LCM | |
|---|---|---|
| Latency | Recursion overhead on every turn | Overhead only when thresholds are crossed |
| Reliability | Model-generated orchestration code | Runtime invariants, schema checks, deterministic fallbacks |
| Recursion safety | Depth caps | Scope reduction guarantees termination structurally |
The strongest read is complementarity. Structured operators as the default path, symbolic recursion reserved for edge cases.
Limitations
Benchmark contamination risk. Opus 4.6 can sometimes recognize OOLONG items from pretraining and answer without true aggregation. The authors filter contaminated traces and still observe the same ordering, though with a smaller margin.
Static benchmarks age quickly. The paper argues for procedurally generated evaluations that synthesize fresh tasks at runtime.
Practical Takeaways
For production teams, LCM points to a clear architecture direction.
- Use deterministic context infrastructure. Append-only history, derived views, compaction thresholds, guaranteed fallback.
- Move repetitive orchestration into runtime operators. Map, validation, retries, and concurrency instead of model-written loops.
- Preserve model autonomy for high-value reasoning while letting the engine enforce execution invariants.
- Treat RLM and LCM as complementary. Structured operators as default, symbolic recursion as escape hatch.
- Optimize for user flow. Most turns should stay near base latency, with overhead only when long-context operations are actually needed.