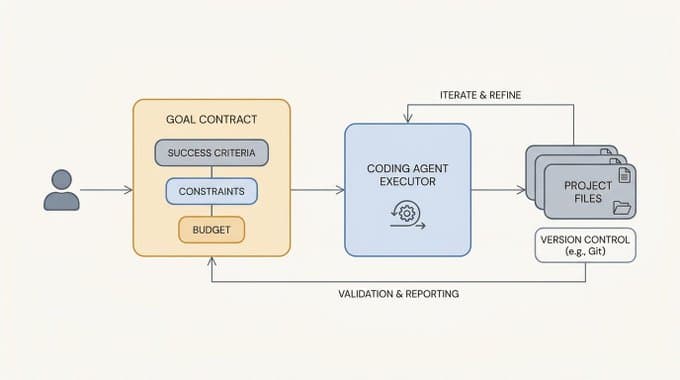
You shipped an AI feature. A support bot answers customer questions in plain language, and the demos looked great. Now you face the question that decides whether you can trust it in production. How do you know its freeform answers are actually good?
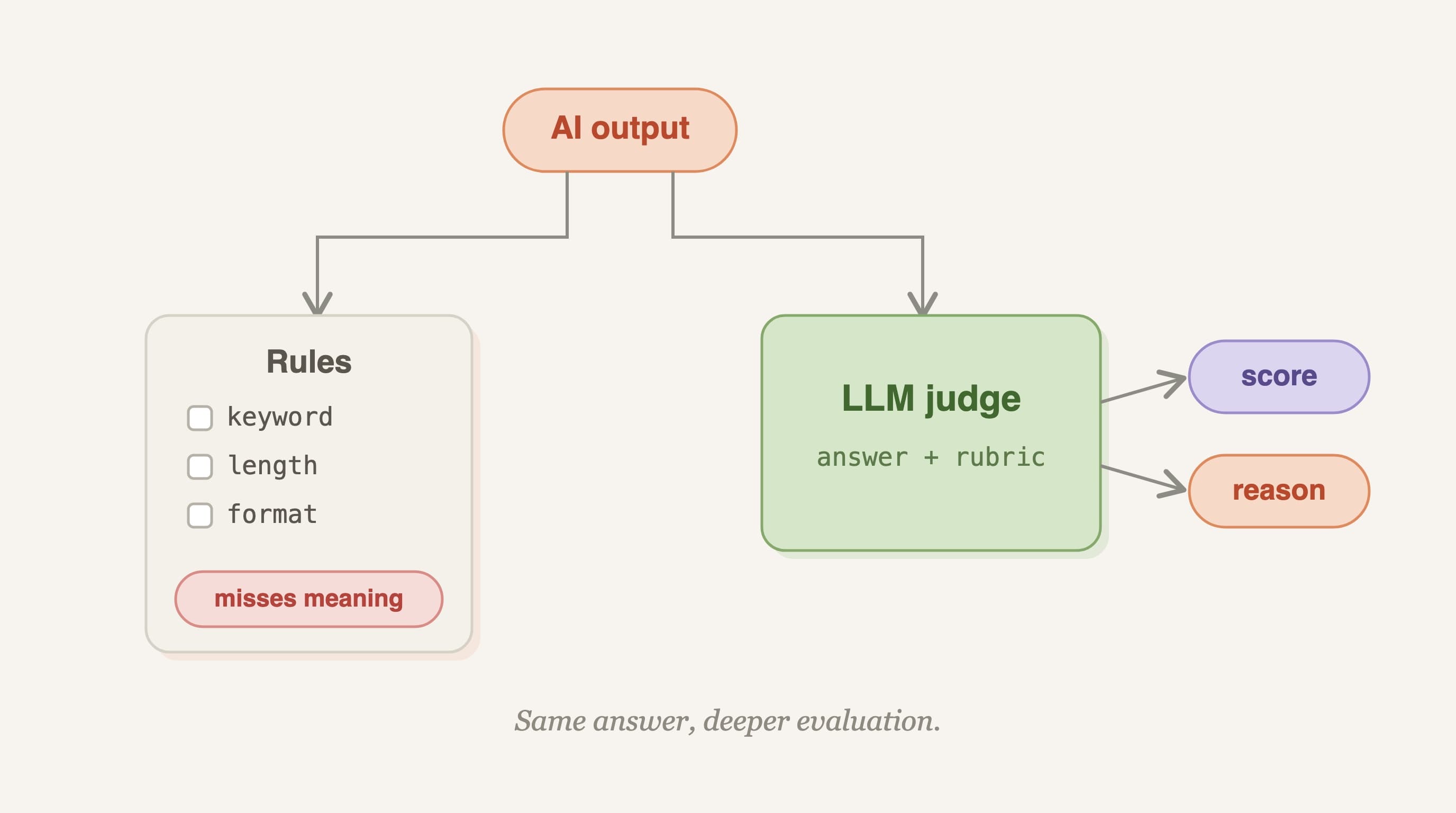
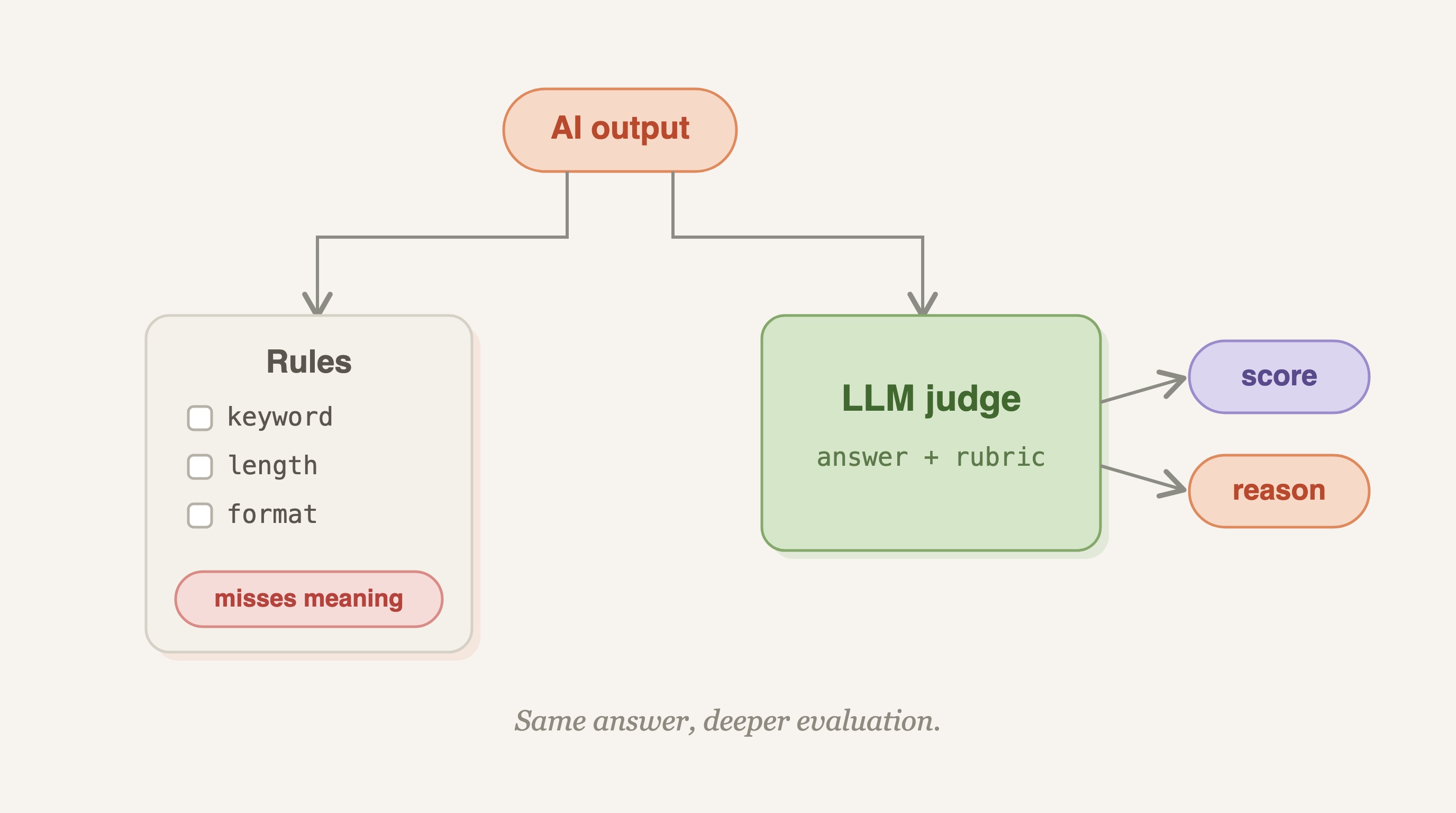
This is where the testing habits you brought from regular software fall apart. A unit test asserts that a function returns exactly 42. A keyword check confirms the word "refund" shows up somewhere in the reply. Both work when there is one right answer. Neither works when a customer can be helped well by ten different wordings and harmed by ten others that happen to contain the right keywords. You need a way to grade quality, not presence.
The practical answer is LLM-as-a-judge: you ask a capable language model to score the output the way a careful human reviewer would. This post explains why deterministic checks break down on open-ended output, what an LLM judge actually is, and how you build a small, trustworthy eval harness step by step. It mirrors our hands-on lab, where you build the judge yourself in a live agent sandbox and point it at a real support bot.
Why deterministic checks fail on open-ended output
Open-ended output has no single correct answer. Ask a support bot to explain a billing charge and a dozen different replies can all be correct, helpful, and on-brand. A few of them are curt, a few ramble, and a few are confidently wrong while sounding polished. The space of acceptable answers is large and fuzzy, which is exactly the shape that rule-based checks cannot cover.
Keyword rules are the usual first attempt, and they fail in both directions. They pass bad answers that contain the magic words and they flag good answers that phrased the same idea differently. String matching, regular expressions, and exact-match assertions all share this blind spot. They measure surface form, not whether the answer was accurate, relevant, and clear. The first lab in the course makes this concrete by having you try to grade real replies with rules and watch them break, so you feel why a different tool is needed before you reach for one.
Once you accept that you are grading qualities rather than checking facts, the next move is to name those qualities. Accuracy, relevance, tone, completeness. These are the things a human reviewer weighs in their head, and they are the things your judge will need to score.
What an LLM judge is
An LLM judge is a language model you prompt to evaluate another model's output against criteria you define. You hand it the original question, the answer under test, and a description of what good looks like. It returns a verdict. That verdict can be a simple yes or no, or a structured score across several dimensions.
The reason this works is that strong models are good at the same recognition task a human reviewer does. They can read a support reply and tell whether it answered the question, stayed on topic, and kept a reasonable tone. Your job is not to trust that ability blindly. Your job is to wrap it in a process that is specific about the rubric, produces machine-readable output, and gets checked against real human judgment. A judge you have not validated is just another opinion. A judge you have validated is an evaluation tool.
What you will build in this lab
The course is six short labs that build one eval harness from nothing. Each lab adds the next piece, and you run all of it in a live agent sandbox in your browser, so there is no setup and you are working with real model calls the whole way.
You start by naming the qualities a judge should score, the ones that keyword rules could never capture. Then you make your first judge call. You send a frontier model a single support reply and ask it for a plain yes or no verdict on whether the reply is good. This is the smallest version of the technique, and it proves the core loop works before you add structure.
From there you give the judge a real rubric. You define three parts, something like accuracy, relevance, and tone, and have the judge score every reply against all three. The output comes back as parseable JSON, which turns one-off opinions into data you can aggregate, sort, and track over time. That shift from prose to structured scores is what makes the judge usable inside an actual eval harness.
Then comes the part that separates a real evaluation from a vibe check. You measure whether the judge can be trusted by comparing its scores against human labels and reporting the agreement. After that you study the biases that LLM judges fall into and harden your judge against them. The final lab is a capstone where you turn the judge's scores and its agreement with humans into a short, honest evaluation report you could hand to your team.
The hard part: judging the judge
It is tempting to stop once the judge returns clean JSON scores. That is the trap. A judge that produces confident numbers can still be wrong in ways you will not notice until production, so the real work is measuring how much you can trust it.
You do this with human agreement. You collect human labels on a set of replies, run your judge on the same set, and compare. If the judge agrees with your human reviewers most of the time, you have evidence it is tracking real quality. If it does not, the scores are noise dressed up as data, and you would rather know that now. Agreement with human labels is the single most important number in this whole process, and it is the one most teams skip.
Bias is the other half. LLM judges have known failure modes. They can favor longer answers, reward a confident tone over a correct one, or drift toward whatever pattern the prompt nudged them into. Two techniques push back. Set temperature to 0 so the same input grades the same way every time, which makes the judge reproducible. Use reason-first scoring, where the judge writes its reasoning before it commits to a number, so the score follows from an argument instead of a snap reaction. Together these make the judge steadier and easier to debug when it disagrees with a human.
What's under the hood
You write real Python in a browser-based sandbox. There is no environment to configure and no API key to hold. The sandbox calls a frontier model through a secure proxy, so your judge code talks to a real LLM while your credentials stay server-side.
The work is ordinary evaluation engineering. You prompt a model to score replies, parse its output as JSON, compare those scores against human labels, and measure agreement. By the end you have a small Python evaluation harness you can lift out and point at your own open-ended tasks. Automated checkpoints verify each step, so you know the judge actually behaves the way you think it does.
Who this is for
This lab is for AI engineers and builders who have shipped something with open-ended output and now need to evaluate it honestly. You should be comfortable calling a model API and reading JSON. You do not need a background in evaluation theory or statistics. The course is rated intermediate because it assumes you can follow code and reason about tradeoffs, not because it expects you to arrive with eval experience. If you have ever looked at a wall of model outputs and wondered how to grade them at scale, this is built for you.
Close
Open-ended AI output is here to stay, and so is the problem of grading it. LLM-as-a-judge gives you a way to measure quality that keyword checks never could, but only if you validate the judge against humans and harden it against its own biases. Build that harness once and you can point it at any open-ended task you ship next.
Want more like this? Check out our courses, explore the rest of our labs, or join the community to ask follow up questions about this post.